Building an Intelligent SQL Query Assistant with Neon, .NET, Azure Functions, and Azure OpenAI service
Learn how to create a SQL Query Assistant with Neon Serverless Postgres AI features.
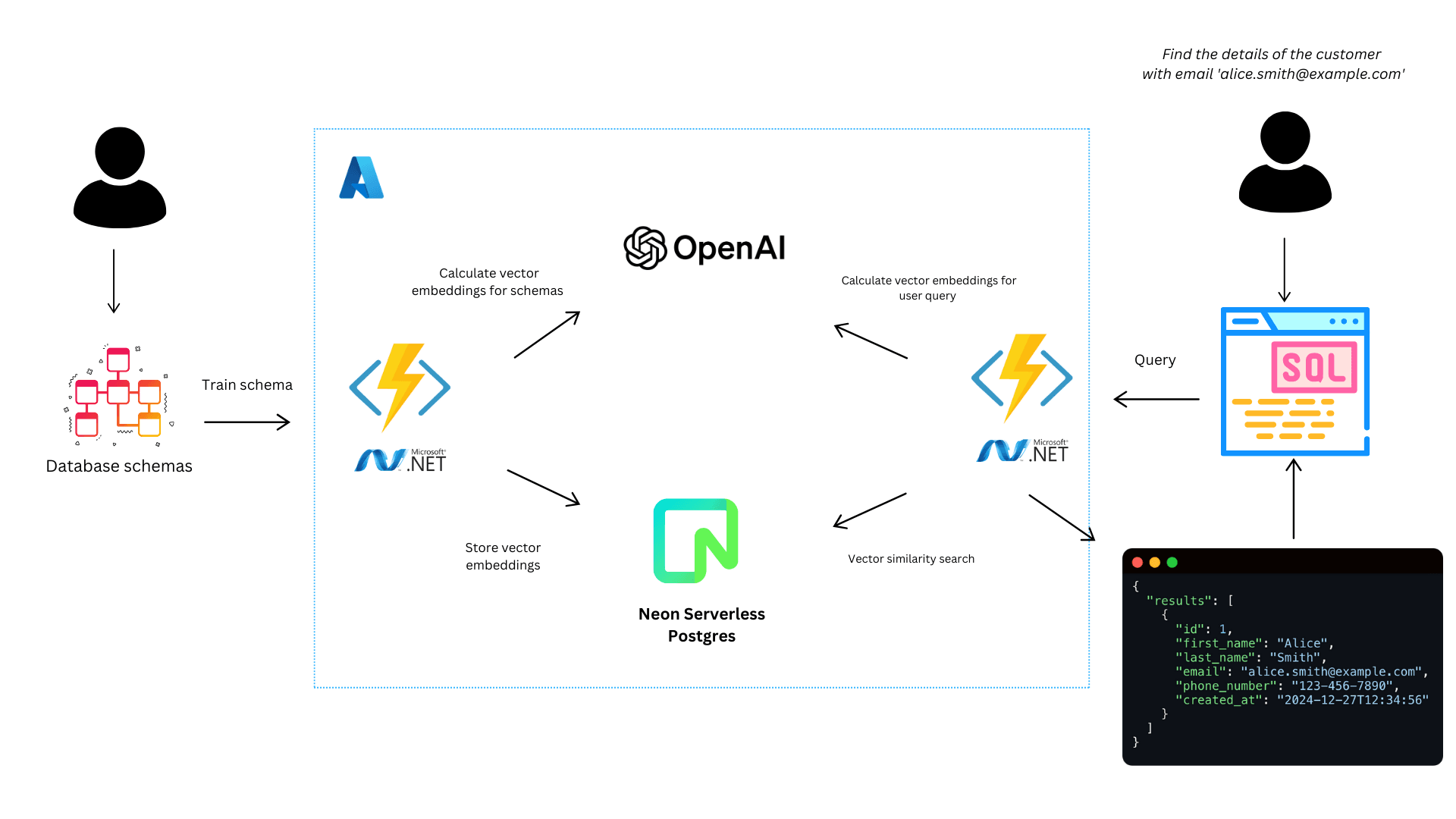
Neon SQL editor provides AI-driven features, such as SQL generation to easily convert natural language requests to SQL. However, there may be situations where you need to build your own AI query assistant for custom needs. For example, you might need tighter integration with your application via query API, add advanced domain-specific logic, hide business-critical data, or support for complex multi-step queries that built-in tools typically don’t handle.
Additionally, creating your assistant gives you control over data handling to comply with standards like GDPR or HIPAA. It lets you ask questions in plain English, translate them into SQL, query the Neon database, and deliver results securely.
In this guide, we’ll show you how to build an intelligent SQL Query Assistant using the following tools:
- .NET Core: To handle the backend logic and API development in C#.
- Azure Functions: To create two serverless APIs:
- SchemaTraining API: Extracts the existing schema from your database, generates vector embeddings, and stores them in Neon.
- QueryAssistant API: Processes user queries, generates SQL commands dynamically, executes them, and returns the results.
- Azure OpenAI SDK: To leverage AI models in .NET code for generating embeddings and translating user queries into SQL.
- Neon: To store vector embeddings and query-related documents based on vector similarity. using the pgvector extension.
- Azure OpenAI Service: To deploy and manage AI models like
gpt-4oandtext-embedding-ada-002efficiently.
You can also quickly jump on the source code hosted on our GitHub and try it yourself.
Setting Up the Neon Project
Prerequisites
Before we begin, make sure you have the following:
- .NET Core SDK
- Azure Functions Core Tools installed
- A free Neon account
- An Azure account with an active subscription
Create a Neon Project
- Navigate to the Neon Console
- Click “New Project”
- Select Azure as your cloud provider
- Choose East US 2 as your region
- Give your project a name (e.g., “sq-data-assistant”)
- Click “Create Project”
Save your connection details – you’ll need these to connect from Azure Function APIs.
Create the Database Tables
Use the Neon SQL editor to create database tables customers and vector_data to store vectors:
-- Create a table to store vector embeddings
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE vector_data (
id SERIAL PRIMARY KEY,
description TEXT NOT NULL,
embedding VECTOR(1536)
);
-- Create a customers Table
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
first_name TEXT NOT NULL,
last_name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE,
phone_number TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Populate the customers table with sample data:
INSERT INTO customers (first_name, last_name, email, phone_number)
VALUES
('Alice', 'Smith', 'alice.smith@example.com', '123-456-7890'),
('Bob', 'Johnson', 'bob.johnson@example.com', '987-654-3210'),
('Charlie', 'Brown', 'charlie.brown@example.com', '555-555-5555'),
('Diana', 'Prince', 'diana.prince@example.com', '111-222-3333'),
('Eve', 'Adams', 'eve.adams@example.com', NULL);Setting Up Azure AI Service to Use Models
Let’s set up Azure AI Service and deploy two models: GPT-4 for analyzing and generating SQL queries and text-embedding-ada-002 for creating vector embeddings for database schema and user queries. These models will power our intelligent SQL assistant.
Create an Azure OpenAI Resource
Before deploying models, you need an Azure OpenAI resource. Follow these steps:
- Go to the Azure Portal:
- Sign in with your Azure account.
- Create a New OpenAI Resource:
- Click Create a resource and search for Azure OpenAI.
- Click Create to start setting up the resource.
- Fill in the Required Fields:
- Subscription: Select your Azure subscription.
- Resource Group: Choose an existing group or create a new one to organize your resources.
- Region: Pick a region where Azure OpenAI is supported.
- Name: Provide a unique name for your resource (e.g.,
MyOpenAIResource).
- Review and Create:
- Click Next until you reach the “Review + Create” tab.
- Review the settings and click Create.
Deploy the Models
Once your Azure OpenAI resource is created, you can deploy the models:
Deploy GPT-4o (For Chat and Query Understanding)
- Go to your Azure OpenAI resource in the Azure Portal.
- Click on the Model catalog tab.
- Find the gpt-4o model in the list.
- Click Deploy and follow the prompts:
- Provide a name for the deployment (e.g.,
gpt4o). - Keep the default settings or adjust based on your needs.
- Provide a name for the deployment (e.g.,
- Wait for the deployment to complete. Once ready, Azure will provide:
- Endpoint URL: The URL to send API requests.
- API Key: The key to authenticate API calls.
Deploy text-embedding-ada-002 (For Embeddings)
- While in the same Model catalog, find the text-embedding-ada-002 model.
- Click Deploy and provide a deployment name (e.g.,
text-embedding-ada-002). - Follow the same steps as above and wait for deployment.
Use the Models
After both models are deployed, you’ll use:
- GPT-4 for processing natural language queries and generating SQL.
- text-embedding-ada-002 to create vector embeddings for schema training and query optimization.
To connect .NET application to these models, we will use the Endpoint URL and API Key together with model names from your Azure OpenAI resource.
Creating the Azure Function App
Project Structure
Here’s how the Azure Function App project’s final structure should look:
SqlQueryAssistant
│ SqlQueryAssistant.sln
|
├───SqlQueryAssistant.Common
│ │ ChatCompletionService.cs
│ │ EmbeddingService.cs
│ │ SchemaService.cs
│ │ SchemaConverter.cs
│ │ SqlExecutorService.cs
│ │ SchemaRetrievalService.cs
│ │ VectorStorageService.cs
│ └───SqlQueryAssistant.Common.csproj
│
├───SqlQueryAssistant.Data
| | customers.sql
| | schema.sql
└───SqlQueryAssistant.Functions
│ host.json
│ local.settings.json
│ QueryAssistantFunction.cs
└───SqlQueryAssistant.Functions.csprojCreate a New .NET Core Project
Open a CLI terminal and run the following commands to create and set up a new .NET project with Azure Function:
dotnet new sln -n SqlQueryAssistant
dotnet new classlib -n SqlQueryAssistant.Common
func --worker-runtime dotnet-isolated -n SqlQueryAssistant.Functions
dotnet sln add SqlQueryAssistant.Common/SqlQueryAssistant.Common.csproj
dotnet sln add SqlQueryAssistant.Functions/SqlQueryAssistant.Functions.csproj
dotnet add SqlQueryAssistant.Functions/SqlQueryAssistant.Functions.csproj reference SqlQueryAssistant.Common/SqlQueryAssistant.Common.csprojInstall Required NuGet Packages
Run the following commands in the terminal to install the required NuGet packages:
dotnet add SqlQueryAssistant.Functions package Microsoft.Azure.Functions.Worker
dotnet add SqlQueryAssistant.Functions package Microsoft.Azure.Functions.Worker.Extensions.Http
dotnet add SqlQueryAssistant.Functions package Newtonsoft.Json
dotnet add SqlQueryAssistant.Common package Npgsql
dotnet add SqlQueryAssistant.Common package Microsoft.Extensions.Configuration.EnvironmentVariables
dotnet add SqlQueryAssistant.Common package Microsoft.Extensions.Configuration.Json
dotnet add SqlQueryAssistant.Common package Azure.AI.OpenAI
dotnet add SqlQueryAssistant.Common package Npgsql.EntityFrameworkCore.PostgreSQLCreate a configuration settings file
If you don’t already have a local.settings.json file created automatically in your SqlQueryAssistant.Functions project, create one at the root of the project. Add your configuration with environment variable values like this:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"FUNCTIONS_WORKER_RUNTIME": "dotnet-isolated",
"AzureOpenAIApiKey": "",
"AzureOpenAIEndpoint": "",
"AzureOpenAIEmbeddingDeploymentName": "",
"AzureOpenAIChatCompletionDeploymentName": ",
"NeonDatabaseConnectionString": ""
}
}Create an Azure Function to Handle HTTP Requests
In your SqlQueryAssistant.Functions project, create a new function called QueryAssistantFunction.cs that handles both schema training and query processing:
using Microsoft.Azure.Functions.Worker;
using Microsoft.Azure.Functions.Worker.Http;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
public class QueryAssistantFunction
{
private readonly ILogger _logger;
private readonly SchemaRetrievalService _schemaRetrievalService;
private readonly SqlExecutorService _sqlExecutorService;
private readonly SchemaService _schemaService;
private readonly VectorStorageService _vectorStorageService;
public QueryAssistantFunction(
ILoggerFactory loggerFactory,
SchemaRetrievalService schemaRetrievalService,
SqlExecutorService sqlExecutorService,
SchemaService schemaService,
VectorStorageService vectorStorageService)
{
_logger = loggerFactory.CreateLogger<QueryAssistantFunction>();
_schemaRetrievalService = schemaRetrievalService;
_sqlExecutorService = sqlExecutorService;
_schemaService = schemaService;
_vectorStorageService = vectorStorageService;
}
[Function("QueryAssistant")]
public async Task<HttpResponseData> QueryAsync(
[HttpTrigger(AuthorizationLevel.Function, "post", Route = "query-assistant")] HttpRequestData req)
{
_logger.LogInformation("Received a request to Query Assistant.");
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
var userQuery = JsonConvert.DeserializeObject<UserQuery>(requestBody);
var schema = await _schemaRetrievalService.GetRelevantSchemaAsync(userQuery.Query);
var generatedSqlQuery = await _schemaRetrievalService.GenerateSqlQuery(userQuery.Query, schema);
var result = await _sqlExecutorService.ExecuteQueryAsync(generatedSqlQuery);
var response = req.CreateResponse(System.Net.HttpStatusCode.OK);
await response.WriteStringAsync(JsonConvert.SerializeObject(result));
return response;
}
[Function("SchemaTraining")]
public async Task<HttpResponseData> TrainSchemaAsync(
[HttpTrigger(AuthorizationLevel.Function, "post", Route = "schema-training")] HttpRequestData req)
{
_logger.LogInformation("Received a request to train schema.");
var schemas = await _schemaService.GetDatabaseSchemaAsync();
await _vectorStorageService.StoreSchemaInVectorDb(schemas);
var response = req.CreateResponse(System.Net.HttpStatusCode.OK);
await response.WriteStringAsync("Schema training completed successfully.");
return response;
}
}
public class UserQuery
{
public string Query { get; set; }
}Retrieving and Storing Database Schema
Create a serviceSchemaService.cs in the SqlQueryAssistant.Common project to retrieve the database schema from Neon. It queries tables (customers) and their columns and prepare the schema data for further embedding process:
using Npgsql;
using Microsoft.Extensions.Configuration;
public class SchemaService
{
private readonly string _connectionString;
public SchemaService(IConfiguration configuration)
{
_connectionString = configuration["NeonDatabaseConnectionString"];
}
public async Task<List<TableSchema>> GetDatabaseSchemaAsync()
{
var tables = new List<TableSchema>();
await using (var connection = new NpgsqlConnection(_connectionString))
{
await connection.OpenAsync();
var getTablesQuery = @"
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema NOT IN ('pg_catalog', 'information_schema');";
await using var command = new NpgsqlCommand(getTablesQuery, connection);
await using var reader = await command.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
var schemaName = reader.GetString(0);
var tableName = reader.GetString(1);
// Open a new connection for retrieving columns to avoid concurrent usage of the same connection
var columns = await GetTableColumnsAsync(schemaName, tableName);
tables.Add(new TableSchema { SchemaName = schemaName, TableName = tableName, Columns = columns });
}
}
return tables;
}
private async Task<List<ColumnSchema>> GetTableColumnsAsync(string schemaName, string tableName)
{
var columns = new List<ColumnSchema>();
// Create a new connection for each query
await using (var connection = new NpgsqlConnection(_connectionString))
{
await connection.OpenAsync();
var columnQuery = @"
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_schema = @schemaName AND table_name = @tableName";
await using var command = new NpgsqlCommand(columnQuery, connection);
command.Parameters.AddWithValue("@schemaName", schemaName);
command.Parameters.AddWithValue("@tableName", tableName);
await using var reader = await command.ExecuteReaderAsync();
while (await reader.ReadAsync())
{
columns.Add(new ColumnSchema
{
ColumnName = reader.GetString(0),
DataType = reader.GetString(1)
});
}
}
return columns;
}
}
public class TableSchema
{
public string SchemaName { get; set; }
public string TableName { get; set; }
public List<ColumnSchema> Columns { get; set; }
}
public class ColumnSchema
{
public string ColumnName { get; set; }
public string DataType { get; set; }
}Generating Embeddings and Storing Them in Neo
Next, we generate vector embeddings using the text-embedding-ada-002 model. These embeddings are used to match user queries with relevant database schemas.
using System.ClientModel;
using Azure;
using Azure.AI.OpenAI;
using OpenAI.Embeddings;
using Microsoft.Extensions.Configuration;
public class EmbeddingService
{
private readonly AzureOpenAIClient _client;
private readonly string _deploymentName;
public EmbeddingService(IConfiguration configuration)
{
var endpoint = new Uri(configuration["AzureOpenAIEndpoint"]);
var apiKey = configuration["AzureOpenAIApiKey"];
_deploymentName = configuration["AzureOpenAIEmbeddingDeploymentName"];
_client = new AzureOpenAIClient(endpoint, new AzureKeyCredential(apiKey));
}
public async Task<List<float>> GetEmbeddingAsync(string input)
{
var embeddingClient = _client.GetEmbeddingClient(_deploymentName);
ClientResult<OpenAIEmbedding> embeddingResult = await embeddingClient.GenerateEmbeddingAsync(input);
if (embeddingResult.Value?.ToFloats().Length > 0)
{
return embeddingResult.Value.ToFloats().ToArray().ToList();
}
throw new InvalidOperationException("No embeddings were returned.");
}
}Store the embeddings in Neon:
using Npgsql;
using Microsoft.Extensions.Configuration;
public class VectorStorageService
{
private readonly string _connectionString;
private readonly EmbeddingService _embeddingService;
public VectorStorageService(IConfiguration configuration, EmbeddingService embeddingService)
{
_connectionString = configuration["NeonDatabaseConnectionString"];
_embeddingService = embeddingService;
}
public async Task StoreSchemaInVectorDb(List<TableSchema> schemas)
{
using (var conn = new NpgsqlConnection(_connectionString))
{
conn.Open();
foreach (var schema in schemas)
{
var schemaString = SchemaConverter.ConvertSchemaToString(schema);
var embedding = await _embeddingService.GetEmbeddingAsync(schemaString);
using (var cmd = new NpgsqlCommand())
{
cmd.Connection = conn;
cmd.CommandText = "INSERT INTO vector_data (description, embedding) VALUES (@description, @embedding)";
cmd.Parameters.AddWithValue("description", schemaString);
cmd.Parameters.AddWithValue("embedding", embedding.ToArray());
cmd.ExecuteNonQuery();
}
}
}
}
}Dynamically Generating SQL Queries
To retrieve the most relevant database schema using a typical Retrieval-Augmented Generation (RAG) approach:
- First, we calculate vector embeddings from the user query.
- Next, we use Neon’s
pgvectorextension and its distance function operator<->to compare these embeddings against stored schema embeddings, identifying the most relevant schema. - After we find matching database schema, we call chat completion endpoint to generate an SQL query for it.
using Npgsql;
using Microsoft.Extensions.Configuration;
public class SchemaRetrievalService
{
private readonly string _connectionString;
private readonly EmbeddingService _embeddingService;
private readonly ChatCompletionService _chatCompletionService;
public SchemaRetrievalService(IConfiguration configuration,
EmbeddingService embeddingService,
ChatCompletionService chatCompletionService)
{
_connectionString = configuration["NeonDatabaseConnectionString"];
_embeddingService = embeddingService;
_chatCompletionService = chatCompletionService;
}
public async Task<TableSchema> GetRelevantSchemaAsync(string userQuery)
{
var queryEmbedding = await _embeddingService.GetEmbeddingAsync(userQuery);
string queryEmbeddingString = string.Join(", ", queryEmbedding);
string generatedSqlQuery = GeneratePredefinedSqlTemplate(queryEmbeddingString);
Console.WriteLine("Generated SQL query: " + generatedSqlQuery);
using var conn = new NpgsqlConnection(_connectionString);
conn.Open();
using var cmd = new NpgsqlCommand(generatedSqlQuery, conn);
var schemaDescription = await cmd.ExecuteScalarAsync();
return SchemaConverter.ConvertStringToSchema(schemaDescription.ToString());
}
public async Task<string> GenerateSqlQuery(string userQuery, TableSchema schema)
{
var prompt =
"Generate an SQL query based on the following database schema and user query.\\n\\n" +
"Database Schema:\\n" +
SchemaConverter.ConvertSchemaToString(schema) + "\\n\\n" +
$"User Query: {userQuery}\\n\\n" +
"Return only the SQL query as plain text, with no formatting, no code blocks (like ```sql), and no additional markers:";
var generatedSqlQuery = await _chatCompletionService.GetChatCompletionAsync(prompt);
return generatedSqlQuery;
}
private string GeneratePredefinedSqlTemplate(string queryEmbeddingString)
{
return $@"
SELECT description
FROM vector_data
ORDER BY embedding <-> '[{queryEmbeddingString}]'
LIMIT 1;";
}
}We convert user queries into meaningful SQL commands by using ChatCompletionService:
using Azure;
using Azure.AI.OpenAI;
using OpenAI.Chat;
using Microsoft.Extensions.Configuration;
public class ChatCompletionService
{
private readonly AzureOpenAIClient _azureOpenAIclient;
private readonly string _deploymentName;
public ChatCompletionService(IConfiguration configuration)
{
var endpoint = new Uri(configuration["AzureOpenAIEndpoint"]);
var apiKey = configuration["AzureOpenAIApiKey"];
_deploymentName = configuration["AzureOpenAIChatCompletionDeploymentName"];
_azureOpenAIclient = new AzureOpenAIClient(endpoint, new AzureKeyCredential(apiKey));
}
public async Task<string> GetChatCompletionAsync(string prompt)
{
var chatClient = _azureOpenAIclient.GetChatClient(_deploymentName);
var completionResult = await chatClient.CompleteChatAsync(
[
new SystemChatMessage("You are a helpful assistant that generates SQL query."),
new UserChatMessage(prompt),
]);
string completionText = completionResult.Value.Content.First().Text.Trim();
return completionText;
}
}
Executing SQL Queries and Returning Results from Neon
Finally, we execute the generated SQL query against Neon to fetch relevant data:
using Npgsql;
using Microsoft.Extensions.Configuration;
public class SqlExecutorService
{
private readonly string _connectionString;
public SqlExecutorService(IConfiguration configuration)
{
_connectionString = configuration["NeonDatabaseConnectionString"];
}
public async Task<List<Dictionary<string, object>>> ExecuteQueryAsync(string sqlQuery)
{
var result = new List<Dictionary<string, object>>();
using (var connection = new NpgsqlConnection(_connectionString))
{
await connection.OpenAsync();
using (var command = new NpgsqlCommand(sqlQuery, connection))
using (var reader = await command.ExecuteReaderAsync())
{
while (await reader.ReadAsync())
{
var row = new Dictionary<string, object>();
for (int i = 0; i < reader.FieldCount; i++)
{
row[reader.GetName(i)] = reader.GetValue(i);
}
result.Add(row);
}
}
}
return result;
}
}Up to now, the function code has been implemented. Now we can run and test it locally.
Run the Project Locally
Navigate to the Functions Project:
cd SqlQueryAssistant.FunctionsRestore Dependencies:
dotnet restoreBuild the Solution:
dotnet buildStart the Azure Functions runtime:
func startYou should see an output similar to:
Azure Functions Core Tools
Version: 4.x.x
Function Runtime Version: 4.0.0.0
Functions:
QueryAssistant: [POST] <http://localhost:7071/api/query-assistant>
SchemaTraining: [POST] <http://localhost:7071/api/schema-training>Test the APIs
Example Query to Test SchemaTraining API
You can call the API using cURL:
curl -X POST <http://localhost:7071/api/schema-training> \\
-H "Content-Type: application/json"When you send the request:
- The API should connect to your Neon database.
- It will retrieve the schema details (tables and columns).
- The API will generate embeddings for the schema using Azure OpenAI and store them in the Neon database using the pgvector extension.
- You should receive a successful response:
{
"status": "Schema training completed successfully."
}Example Query to Test QueryAssistant API
When calling the QueryAssistant API, you can send the natural language input in the body of the request like this:
Input (Natural Language Query):
curl -X POST <http://localhost:7071/api/query-assistant> \\
-H "Content-Type: application/json" \\
-d '{
"Query":
"Find the details of the customer with email 'alice.smith@example.com'"
}'API Output:
{
"results": [
{
"id": 1,
"firstName": "Alice",
"lastName": "Smith",
"email": "alice.smith@example.com",
"phoneNumber": "123-456-7890",
"createdAt": "2024-12-27T12:34:56"
}
]
}Deploy to Azure
Publish the Function App
If everything works locally, you can deploy the function app to Azure:
func azure functionapp publish QueryAssistantFunctionFuture Improvements
Great! You did it! With this foundation, you can expand the capabilities of our SQL Query Assistant with other Neon features.
Database Branching: You can create isolated branches of your database, perfect for testing changes without affecting the main database. For example, you can create a branch to test new SQL assistant features like testing embeddings generation for a new schema branch.
Multi-Database Support: Extend the project to support multiple Neon databases, allowing the assistant to query across different datasets or tenants.
Conclusion
In conclusion, we’ve built a smart SQL Query Assistant using .NET Core, Azure Functions, Neon, and Azure OpenAI. This tool makes it easy to work with your Neon database by letting you ask questions in plain English, turn them into SQL, run the query, and simply show the results.
Additional Resources
- Connect an Entity Framework application to Neon
- Optimize pgvector search
- Building AI-Powered Chatbots with Azure AI Studio and Neon
- AI app architecture: vector database per tenant demo
Try it
You can check out our GitHub repository, and give us any feedback on our Discord server!
Neon is a serverless Postgres platform that helps teams ship faster via instant provisioning, autoscaling, and database branching. We have a Free Plan – you can get started without a credit card.



